Шаги
Вычисление дисперсии выборки
-
Запишите значения выборки. В большинстве случаев статистикам доступны только выборки определенных генеральных совокупностей. Например, как правило, статистики не анализируют расходы на содержание совокупности всех автомобилей в России – они анализируют случайную выборку из нескольких тысяч автомобилей. Такая выборка поможет определить средние расходы на автомобиль, но, скорее всего, полученное значение будет далеко от реального.
- Например, проанализируем количество булочек, проданных в кафе за 6 дней, взятых в случайном порядке. Выборка имеет следующий вид: 17, 15, 23, 7, 9, 13. Это выборка, а не совокупность, потому что у нас нет данных о проданных булочках за каждый день работы кафе.
- Если вам дана совокупность, а не выборка значений, перейдите к следующему разделу.
-
Запишите формулу для вычисления дисперсии выборки. Дисперсия является мерой разброса значений некоторой величины. Чем ближе значение дисперсии к нулю, тем ближе значения сгруппированы друг к другу. Работая с выборкой значений, используйте следующую формулу для вычисления дисперсии:
- s 2 {\displaystyle s^{2}} = ∑[( x i {\displaystyle x_{i}} - x̅) 2 {\displaystyle ^{2}} ] / (n - 1)
- s 2 {\displaystyle s^{2}} – это дисперсия. Дисперсия измеряется в квадратных единицах измерения.
- x i {\displaystyle x_{i}} – каждое значение в выборке.
- x i {\displaystyle x_{i}} нужно вычесть x̅, возвести в квадрат, а затем сложить полученные результаты.
- x̅ – выборочное среднее (среднее значение выборки).
- n – количество значений в выборке.
-
Вычислите среднее значение выборки. Оно обозначается как x̅. Среднее значение выборки вычисляется как обычное среднее арифметическое: сложите все значения в выборке, а затем полученный результат разделите на количество значений в выборке.
- В нашем примере сложите значения в выборке: 15 + 17 + 23 + 7 + 9 + 13 = 84
Теперь результат разделите на количество значений в выборке (в нашем примере их 6): 84 ÷ 6 = 14.
Выборочное среднее x̅ = 14. - Выборочное среднее – это центральное значение, вокруг которого распределены значения в выборке. Если значения в выборке группируются вокруг выборочного среднего, то дисперсия мала; в противном случае дисперсия велика.
- В нашем примере сложите значения в выборке: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Вычтите выборочное среднее из каждого значения в выборке. Теперь вычислите разность x i {\displaystyle x_{i}} - x̅, где x i {\displaystyle x_{i}} – каждое значение в выборке. Каждый полученный результат свидетельствует о мере отклонения конкретного значения от выборочного среднего, то есть как далеко это значение находится от среднего значения выборки.
- В нашем примере:
x 1 {\displaystyle x_{1}} - x̅ = 17 - 14 = 3
x 2 {\displaystyle x_{2}} - x̅ = 15 - 14 = 1
x 3 {\displaystyle x_{3}} - x̅ = 23 - 14 = 9
x 4 {\displaystyle x_{4}} - x̅ = 7 - 14 = -7
x 5 {\displaystyle x_{5}} - x̅ = 9 - 14 = -5
x 6 {\displaystyle x_{6}} - x̅ = 13 - 14 = -1 - Правильность полученных результатов легко проверить, так как их сумма должна равняться нулю. Это связано с определением среднего значения, так как отрицательные значения (расстояния от среднего значения до меньших значений) полностью компенсируются положительными значениями (расстояниями от среднего значения до больших значений).
- В нашем примере:
-
Как отмечалось выше, сумма разностей x i {\displaystyle x_{i}} - x̅ должна быть равна нулю. Это означает, что средняя дисперсия всегда равна нулю, что не дает никакого представления о разбросе значений некоторой величины. Для решения этой проблемы возведите в квадрат каждую разность x i {\displaystyle x_{i}} - x̅. Это приведет к тому, что вы получите только положительные числа, которые при сложении никогда не дадут 0.
- В нашем примере:
( x 1 {\displaystyle x_{1}} - x̅) 2 = 3 2 = 9 {\displaystyle ^{2}=3^{2}=9}
(x 2 {\displaystyle (x_{2}} - x̅) 2 = 1 2 = 1 {\displaystyle ^{2}=1^{2}=1}
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Вы нашли квадрат разности - x̅) 2 {\displaystyle ^{2}} для каждого значения в выборке.
- В нашем примере:
-
Вычислите сумму квадратов разностей. То есть найдите ту часть формулы, которая записывается так: ∑[( x i {\displaystyle x_{i}} - x̅) 2 {\displaystyle ^{2}} ]. Здесь знак Σ означает сумму квадратов разностей для каждого значения x i {\displaystyle x_{i}} в выборке. Вы уже нашли квадраты разностей (x i {\displaystyle (x_{i}} - x̅) 2 {\displaystyle ^{2}} для каждого значения x i {\displaystyle x_{i}} в выборке; теперь просто сложите эти квадраты.
- В нашем примере: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Полученный результат разделите на n - 1, где n – количество значений в выборке. Некоторое время назад для вычисления дисперсии выборки статистики делили результат просто на n; в этом случае вы получите среднее значение квадрата дисперсии, которое идеально подходит для описания дисперсии данной выборки. Но помните, что любая выборка – это лишь небольшая часть генеральной совокупности значений. Если взять другую выборку и выполнить такие же вычисления, вы получите другой результат. Как выяснилось, деление на n - 1 (а не просто на n) дает более точную оценку дисперсии генеральной совокупности, в чем вы и заинтересованы. Деление на n – 1 стало общепринятым, поэтому оно включено в формулу для вычисления дисперсии выборки.
- В нашем примере выборка включает 6 значений, то есть n = 6.
Дисперсия выборки = s 2 = 166 6 − 1 = {\displaystyle s^{2}={\frac {166}{6-1}}=} 33,2
- В нашем примере выборка включает 6 значений, то есть n = 6.
-
Отличие дисперсии от стандартного отклонения. Заметьте, что в формуле присутствует показатель степени, поэтому дисперсия измеряется в квадратных единицах измерения анализируемой величины. Иногда такой величиной довольно сложно оперировать; в таких случаях пользуются стандартным отклонением, которое равно квадратному корню из дисперсии. Именно поэтому дисперсия выборки обозначается как s 2 {\displaystyle s^{2}} , а стандартное отклонение выборки – как s {\displaystyle s} .
- В нашем примере стандартное отклонение выборки: s = √33,2 = 5,76.
Вычисление дисперсии совокупности
-
Проанализируйте некоторую совокупность значений. Совокупность включает в себя все значения рассматриваемой величины. Например, если вы изучаете возраст жителей Ленинградской области, то совокупность включает возраст всех жителей этой области. В случае работы с совокупностью рекомендуется создать таблицу и внести в нее значения совокупности. Рассмотрим следующий пример:
- В некоторой комнате находятся 6 аквариумов. В каждом аквариуме обитает следующее количество рыб:
x 1 = 5 {\displaystyle x_{1}=5}
x 2 = 5 {\displaystyle x_{2}=5}
x 3 = 8 {\displaystyle x_{3}=8}
x 4 = 12 {\displaystyle x_{4}=12}
x 5 = 15 {\displaystyle x_{5}=15}
x 6 = 18 {\displaystyle x_{6}=18}
- В некоторой комнате находятся 6 аквариумов. В каждом аквариуме обитает следующее количество рыб:
-
Запишите формулу для вычисления дисперсии генеральной совокупности. Так как в совокупность входят все значения некоторой величины, то приведенная ниже формула позволяет получить точное значение дисперсии совокупности. Для того чтобы отличить дисперсию совокупности от дисперсии выборки (значение которой является лишь оценочным), статистики используют различные переменные:
- σ 2 {\displaystyle ^{2}} = (∑( x i {\displaystyle x_{i}} - μ) 2 {\displaystyle ^{2}} ) / n
- σ 2 {\displaystyle ^{2}} – дисперсия совокупности (читается как «сигма в квадрате»). Дисперсия измеряется в квадратных единицах измерения.
- x i {\displaystyle x_{i}} – каждое значение в совокупности.
- Σ – знак суммы. То есть из каждого значения x i {\displaystyle x_{i}} нужно вычесть μ, возвести в квадрат, а затем сложить полученные результаты.
- μ – среднее значение совокупности.
- n – количество значений в генеральной совокупности.
-
Вычислите среднее значение совокупности. При работе с генеральной совокупностью ее среднее значение обозначается как μ (мю). Среднее значение совокупности вычисляется как обычное среднее арифметическое: сложите все значения в генеральной совокупности, а затем полученный результат разделите на количество значений в генеральной совокупности.
- Имейте в виду, что средние величины не всегда вычисляются как среднее арифметическое.
- В нашем примере среднее значение совокупности: μ = 5 + 5 + 8 + 12 + 15 + 18 6 {\displaystyle {\frac {5+5+8+12+15+18}{6}}} = 10,5
-
Вычтите среднее значение совокупности из каждого значения в генеральной совокупности. Чем ближе значение разности к нулю, тем ближе конкретное значение к среднему значению совокупности. Найдите разность между каждым значением в совокупности и ее средним значением, и вы получите первое представление о распределении значений.
- В нашем примере:
x 1 {\displaystyle x_{1}} - μ = 5 - 10,5 = -5,5
x 2 {\displaystyle x_{2}} - μ = 5 - 10,5 = -5,5
x 3 {\displaystyle x_{3}} - μ = 8 - 10,5 = -2,5
x 4 {\displaystyle x_{4}} - μ = 12 - 10,5 = 1,5
x 5 {\displaystyle x_{5}} - μ = 15 - 10,5 = 4,5
x 6 {\displaystyle x_{6}} - μ = 18 - 10,5 = 7,5
- В нашем примере:
-
Возведите в квадрат каждый полученный результат. Значения разностей будут как положительными, так и отрицательными; если нанести эти значения на числовую прямую, то они будут лежать справа и слева от среднего значения совокупности. Это не годится для вычисления дисперсии, так как положительные и отрицательные числа компенсируют друг друга. Поэтому возведите в квадрат каждую разность, чтобы получить исключительно положительные числа.
- В нашем примере:
( x i {\displaystyle x_{i}} - μ) 2 {\displaystyle ^{2}} для каждого значения совокупности (от i = 1 до i = 6):
(-5,5) 2 {\displaystyle ^{2}} = 30,25
(-5,5) 2 {\displaystyle ^{2}} , где x n {\displaystyle x_{n}} – последнее значение в генеральной совокупности. - Для вычисления среднего значения полученных результатов нужно найти их сумму и разделить ее на n:(( x 1 {\displaystyle x_{1}} - μ) 2 {\displaystyle ^{2}} + ( x 2 {\displaystyle x_{2}} - μ) 2 {\displaystyle ^{2}} + ... + ( x n {\displaystyle x_{n}} - μ) 2 {\displaystyle ^{2}} ) / n
- Теперь запишем приведенное объяснение с использованием переменных: (∑( x i {\displaystyle x_{i}} - μ) 2 {\displaystyle ^{2}} ) / n и получим формулу для вычисления дисперсии совокупности.
- В нашем примере:
Основными обобщающими показателями вариации в статистике являются дисперсии и среднее квадратическое отклонение.
Дисперсия это средняя арифметическая квадратов отклонений каждого значения признака от общей средней. Дисперсия обычно называется средним квадратом отклонений и обозначается 2 . В зависимости от исходных данных дисперсия может вычисляться по средней арифметической простой или взвешенной:
дисперсия невзвешенная (простая);

дисперсия
взвешенная.
дисперсия
взвешенная.
Среднее квадратическое отклонение это обобщающая характеристика абсолютных размеров вариации признака в совокупности. Выражается оно в тех же единицах измерения, что и признак (в метрах, тоннах, процентах, гектарах и т. д.).
Среднее квадратическое отклонение представляет собой корень квадратный из дисперсии и обозначается :

среднее
квадратическое отклонение невзвешенное;
среднее
квадратическое отклонение невзвешенное;

среднее
квадратическое отклонение взвешенное.
среднее
квадратическое отклонение взвешенное.
Среднее квадратическое отклонение является мерилом надежности средней. Чем меньше среднее квадратическое отклонение, тем лучше средняя арифметическая отражает всю представляемую совокупность.
Вычислению среднего квадратического отклонения предшествует расчет дисперсии.
Порядок расчета дисперсии взвешенной следующий:
1) определяют среднюю арифметическую взвешенную:
2) рассчитывают отклонения вариантов от средней:
3) возводят в квадрат отклонение каждого варианта от средней:
4) умножают квадраты отклонений на веса (частоты):
5) суммируют полученные произведения:
![]()
6) полученную сумму делят на сумму весов:

Пример 2.1

Исчислим среднюю арифметическую взвешенную:

Значения отклонений от средней и их квадратов представлены в таблице. Определим дисперсию:

Среднее квадратическое отклонение будет равно:

Если исходные данные представлены в виде интервального ряда распределения , то сначала нужно определить дискретное значение признака, а затем применить изложенный метод.
Пример 2.2
Покажем расчет дисперсии для интервального ряда на данных о распределении посевной площади колхоза по урожайности пшеницы.

Средняя арифметическая равна:

Исчислим дисперсию:

6.3. Расчет дисперсии по формуле по индивидуальным данным
Техника вычисления дисперсии сложна, а при больших значениях вариантов и частот может быть громоздкой. Расчеты можно упростить, используя свойства дисперсии.
Дисперсия имеет следующие свойства.
1. Уменьшение или увеличение весов (частот) варьирующего признака в определенное число раз дисперсию не изменяет.
2. Уменьшение или увеличение каждого значения признака на одну и ту же постоянную величину А дисперсию не изменяет.
3. Уменьшение или увеличение каждого значения признака в какое-то число раз k соответственно уменьшает или увеличивает дисперсию в k 2 раз, а среднее квадратическое отклонение в k раз.
4. Дисперсия признака относительно произвольной величины всегда больше дисперсии относительно средней арифметической на квадрат разности между средней и произвольной величинами:
![]()
Если А 0, то приходим к следующему равенству:
т. е. дисперсия признака равна разности между средним квадратом значений признака и квадратом средней.
Каждое свойство при расчете дисперсии может быть применено самостоятельно или в сочетании с другими.
Порядок расчета дисперсии простой:
1) определяют среднюю арифметическую :
2) возводят в квадрат среднюю арифметическую:

3) возводят в квадрат отклонение каждого варианта ряда:
х i 2 .
4) находят сумму квадратов вариантов:
5) делят сумму квадратов вариантов на их число, т. е. определяют средний квадрат:
6) определяют разность между средним квадратом признака и квадратом средней:
Пример 3.1 Имеются следующие данные о производительности труда рабочих:

Произведем следующие расчеты:
![]()
Наряду с изучением вариации признака по всей по всей совокупности в целом часто бывает необходимо проследить количественные изменения признака по группам, на которые разделяется совокупность, а также и между группами. Такое изучение вариации достигается посредством вычисления и анализа различных видов дисперсии.
Выделяют дисперсию общую, межгрупповую и внутригрупповую
.
Общая дисперсия σ 2
измеряет вариацию признака по всей совокупности под влиянием всех факторов, обусловивших эту вариацию, .
Межгрупповая дисперсия (δ) характеризует систематическую вариацию, т.е. различия в величине изучаемого признака, возникающие под влиянием признака-фактора, положенного в основание группировки. Она рассчитывается по формуле:
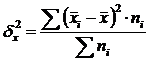 .
.
Внутригрупповая дисперсия (σ)
отражает случайную вариацию, т.е. часть вариации, происходящую под влиянием неучтенных факторов и не зависящую от признака-фактора, положенного в основание группировки. Она вычисляется по формуле:
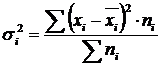 .
.
Средняя из внутригрупповых дисперсий
:  .
.
Существует закон, связывающий 3 вида дисперсии. Общая дисперсия равна сумме средней из внутригрупповых и межгрупповой дисперсии: ![]() .
.
Данное соотношение называют правилом сложения дисперсий
.
В анализе широко используется показатель, представляющий собой долю межгрупповой дисперсии в общей дисперсии. Он носит название эмпирического коэффициента детерминации (η 2):
.
Корень квадратный из эмпирического коэффициента детерминации носит название эмпирического корреляционного отношения (η)
:
 .
.
Оно характеризует влияние признака, положенного в основание группировки, на вариацию результативного признака. Эмпирическое корреляционное отношение изменяется в пределах от 0 до 1.
Покажем его практическое использование на следующем примере (табл. 1).
Пример №1 . Таблица 1 - Производительность труда двух групп рабочих одного из цехов НПО «Циклон»
Рассчитаем общую и групповые средние и дисперсии:
Исходные данные для вычисления средней из внутригрупповых и межгрупповой дисперсии представлены в табл. 2.
Таблица 2
Расчет и δ 2 по двум группам рабочих.
|
Группы рабочих | Численность рабочих, чел. | Средняя, дет./смен. | Дисперсия |
| Прошедшие техническое обучение | 5 | 95 | 42,0 |
| Не прошедшие техническое обучение | 5 | 81 | 231,2 |
| Все рабочие | 10 | 88 | 185,6 |
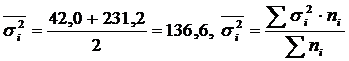 .
.
Межгрупповая дисперсия
Общая дисперсия:
Таким образом, эмпирическое корреляционное соотношение: .
Наряду с вариацией количественных признаков может наблюдаться и вариация качественных признаков. Такое изучение вариации достигается посредством вычисления следующих видов дисперсий:
Внутригрупповая дисперсия доли определяется по формуле
где n i – численность единиц в отдельных группах.Доля изучаемого признака во всей совокупности, которая определяется по формуле:
Три вида дисперсии связаны между собой следующим образом:
Это соотношение дисперсий называется теоремой сложения дисперсий доли признака.
Дисперсия — это мера рассеяния, описывающая сравнительное отклонение между значениями данных и средней величиной. Является наиболее используемой мерой рассеяния в статистике, вычисляемая путем суммирования, возведенного в квадрат, отклонения каждого значения данных от средней величины. Формула для вычисления дисперсии представлена ниже:
![]()
s 2 – дисперсия выборки;
x ср — среднее значение выборки;
n — размер выборки (количество значений данных),
(x i – x ср) — отклонение от средней величины для каждого значения набора данных.
Для лучшего понимания формулы, разберем пример. Я не очень люблю готовку, поэтому занятием этим занимаюсь крайне редко. Тем не менее, чтобы не умереть с голоду, время от времени мне приходится подходить к плите для реализации замысла по насыщению моего организма белками, жирами и углеводами. Набор данных, редставленный ниже, показывает, сколько раз Ренат готовит пищу каждый месяц:
Первым шагом при вычислении дисперсии является определение среднего значения выборки, которое в нашем примере равняется 7,8 раза в месяц. Остальные вычисления можно облегчить с помощью следующей таблицы.

Финальная фаза вычисления дисперсии выглядит так:
![]()
Для тех, кто любит производить все вычисления за один раз, уравнение будет выглядеть следующим образом:
Использование метода «сырого счета» (пример с готовкой)
Существует более эффективный способ вычисления дисперсии, известный как метод «сырого счета». Хотя с первого взгляда уравнение может показаться весьма громоздким, на самом деле оно не такое уж страшное. Можете в этом удостовериться, а потом и решите, какой метод вам больше нравится.

— сумма каждого значения данных после возведения в квадрат,
— квадрат суммы всех значений данных.
Не теряйте рассудок прямо сейчас. Позвольте представить все это в виде таблицы, и тогда вы увидите, что вычислений здесь меньше, чем в предыдущем примере.


Как видите, результат получился тот же, что и при использовании предыдущего метода. Достоинства данного метода становятся очевидными по мере роста размера выборки (n).
Расчет дисперсии в Excel
Как вы уже, наверное, догадались, в Excel присутствует формула, позволяющая рассчитать дисперсию. Причем, начиная с Excel 2010 можно найти 4 разновидности формулы дисперсии:
1) ДИСП.В – Возвращает дисперсию по выборке. Логические значения и текст игнорируются.
2) ДИСП.Г — Возвращает дисперсию по генеральной совокупности. Логические значения и текст игнорируются.
3) ДИСПА — Возвращает дисперсию по выборке с учетом логических и текстовых значений.
4) ДИСПРА — Возвращает дисперсию по генеральной совокупности с учетом логических и текстовых значений.
Для начала разберемся в разнице между выборкой и генеральной совокупностью. Назначение описательной статистики состоит в том, чтобы суммировать или отображать данные так, чтобы оперативно получать общую картину, так сказать, обзор. Статистический вывод позволяет делать умозаключения о какой-либо совокупности на основе выборки данных из этой совокупности. Совокупность представляет собой все возможные исходы или измерения, представляющие для нас интерес. Выборка — это подмножество совокупности.
Например, нас интересует совокупность группы студентов одного из Российских ВУЗов и нам необходимо определить средний бал группы. Мы можем посчитать среднюю успеваемость студентов, и тогда полученная цифра будет параметром, поскольку в наших расчетах будет задействована целая совокупность. Однако, если мы хотим рассчитать средний бал всех студентов нашей страны, тогда эта группа будет нашей выборкой.
Разница в формуле расчета дисперсии между выборкой и совокупностью заключается в знаменателе. Где для выборки он будет равняться (n-1), а для генеральной совокупности только n.
Теперь разберемся с функциями расчета дисперсии с окончаниями А, в описании которых сказано, что при расчете учитываются текстовые и логические значения. В данном случае при расчете дисперсии определенного массива данных, где встречаются не числовые значения, Excel будет интерпретировать текстовые и ложные логические значения как равными 0, а истинные логические значения как равными 1.
Итак, если у вас есть массив данных, рассчитать его дисперсию ни составит никакого труда, воспользовавшись одной из перечисленных выше функций Excel.

Дисперсией (рассеянием) случайной величины называется математическое ожидание квадрата отклонения случайной величины от ее математического ожидания:
Для вычисления дисперсии можно использовать слегка преобразованную формулу
так как М(Х)
, 2 и –
постоянные величины. Таким образом,
–
постоянные величины. Таким образом,
4.2.2. Свойства дисперсии
Свойство 1. Дисперсия постоянной величины равна нулю. Действительно, по определению
Свойство 2. Постоянный множитель можно выносить за знак дисперсии с возведением его в квадрат.
Доказательство
Центрированной случайной величиной называется отклонение случайной величины от ее математического ожидания:

Центрированная величина обладает двумя удобными для преобразования свойствами:
Свойство 3. Если случайные величины Х иY независимы, то
Доказательство
. Обозначим .
Тогдаи.
.
Тогдаи.
Во втором слагаемом в силу независимости случайных величин и свойств центрированных случайных величин
Пример 4.5.
Еслиa
иb
– постоянные,
тоD(a
Х+
b
)=
D
(a
Х)+
D
(b
)= .
.
4.2.3. Среднее квадратическое отклонение
Дисперсия, как
характеристика разброса случайной
величины, имеет один недостаток. Если,
например, Х
– ошибка измерения имеет размерность
ММ
,
то дисперсия имеет размерность
 .
Поэтому часто предпочитают пользоваться
другой характеристикой разброса –средним
квадратическим отклонением
,
которое равно корню квадратному из
дисперсии
.
Поэтому часто предпочитают пользоваться
другой характеристикой разброса –средним
квадратическим отклонением
,
которое равно корню квадратному из
дисперсии

Среднее квадратическое отклонение имеет ту же размерность, что и сама случайная величина.
Пример 4.6. Дисперсия числа появления события в схеме независимых испытаний
Производится n независимых испытаний и вероятность появления события в каждом испытании равнар . Выразим, как и прежде, число появления событияХ через число появления события в отдельных опытах:
Так как опыты независимы, то и связанные
с опытами случайные величины
 независимы. А в силу независимости
независимы. А в силу независимости имеем
имеем
Но каждая из случайных величин имеет закон распределения (пример 3.2)
|
| ||

и
 (пример 4.4). Поэтому, по определению
дисперсии:
(пример 4.4). Поэтому, по определению
дисперсии:
где q =1- p .
В итоге имеем
 ,
,
Среднее квадратическое отклонение
числа появлений события в n
независимых опытах равно .
.
4.3. Моменты случайных величин
Помимо уже рассмотренных случайные величины имеют множество других числовых характеристик.
Начальным
моментом
k
Х
( )
называется математическое ожиданиеk
-й
степени этой случайной величины.
)
называется математическое ожиданиеk
-й
степени этой случайной величины.
Центральным моментом k -го порядка случайной величиныХ называется математическое ожиданиеk -ой степени соответствующей центрированной величины.

Легко видеть, что центральный момент первого порядка всегда равен нулю, центральный момент второго порядка равен дисперсии, так как .
Центральный момент третьего порядка дает представление об асимметрии распределения случайной величины. Моменты порядка выше второго употребляются сравнительно редко, поэтому мы ограничимся только самими понятиями о них.
4.4. Примеры нахождения законов распределения
Рассмотрим примеры нахождения законов распределения случайных величин и их числовых характеристик.
Пример 4.7.
Составить закон распределения числа
попаданий в цель при трех выстрелах по
мишени, если вероятность попадания при
каждом выстреле равна 0,4. Найти интегральную
функцию F
(х)
для
полученного распределения дискретной
случайной величиныХ
и начертить
ее график. Найти математическое ожиданиеM
(X
)
,
дисперсиюD
(X
)
и среднее квадратическое отклонение
 (Х
)
случайной величиныX
.
(Х
)
случайной величиныX
.
Решение
1) Дискретная случайная величина Х – число попаданий в цель при трех выстрелах – может принимать четыре значения:0, 1, 2, 3 . Вероятность того, что она примет каждое из них, найдем по формуле Бернулли при:n =3,p =0,4,q =1- p =0,6 иm =0, 1, 2, 3:
Получим вероятности возможных значений Х :;
Составим искомый закон распределения случайной величины Х :
Контроль: 0,216+0,432+0,288+0,064=1.
Построим многоугольник распределения полученной случайной величины Х . Для этого в прямоугольной системе координат отметим точки (0; 0,216), (1; 0,432), (2; 0,288), (3; 0,064). Соединим эти точки отрезками прямых, полученная ломаная и есть искомый многоугольник распределения (рис. 4.1).

2) Если х 0,
то F
(х)
=0.
Действительно, значений, меньших нуля,
величина Х
не принимает. Следовательно, при всех
х
0,
то F
(х)
=0.
Действительно, значений, меньших нуля,
величина Х
не принимает. Следовательно, при всех
х
 0
, пользуясь определениемF
(х)
,
получим F
(х)
=P
(X
<
x
)
=0
(как вероятность невозможного события).
0
, пользуясь определениемF
(х)
,
получим F
(х)
=P
(X
<
x
)
=0
(как вероятность невозможного события).
Если 0 ,
тоF
(X
)
=0,216.
Действительно, в этом случаеF
(х)
=P
(X
<
x
)
=
=P
(-
,
тоF
(X
)
=0,216.
Действительно, в этом случаеF
(х)
=P
(X
<
x
)
=
=P
(-
 <
X
<
X 0)+
P
(0<
X
<
x
)
=0,216+0=0,216.
0)+
P
(0<
X
<
x
)
=0,216+0=0,216.
Если взять, например, х =0,2, тоF (0,2)=P (X <0,2) . Но вероятность событияХ <0,2 равна 0,216, так как случайная величинаХ лишь в одном случае принимает значение меньшее 0,2, а именно0 с вероятностью 0,216.
Если 1 ,
то
,
то
Действительно, Х может принять значение 0 с вероятностью 0,216 и значение 1 с вероятностью 0,432; следовательно, одно из этих значений, безразлично какое,Х может принять (по теореме сложения вероятностей несовместных событий) с вероятностью 0,648.
Если 2 ,
то рассуждая аналогично, получимF
(х)
=0,216+0,432 +
+ 0,288=0,936. Действительно, пусть, например,х
=3. ТогдаF
(3)=P
(X
<3)
выражает вероятность событияX
<3 –
стрелок сделает меньше трех попаданий,
т.е. ноль, один или два. Применяя теорему
сложения вероятностей, получим указанное
значение функцииF
(х)
.
,
то рассуждая аналогично, получимF
(х)
=0,216+0,432 +
+ 0,288=0,936. Действительно, пусть, например,х
=3. ТогдаF
(3)=P
(X
<3)
выражает вероятность событияX
<3 –
стрелок сделает меньше трех попаданий,
т.е. ноль, один или два. Применяя теорему
сложения вероятностей, получим указанное
значение функцииF
(х)
.
Если x
>3, тоF
(х)
=0,216+0,432+0,288+0,064=1.
Действительно, событиеX
 является
достоверным и вероятность его равна
единице, аX
>3 –
невозможным. Учитывая, что
является
достоверным и вероятность его равна
единице, аX
>3 –
невозможным. Учитывая, что
F
(х)
=P
(X
<
x
)
=P
(X 3)
+
P
(3<
X
<
x
)
,
получим указанный результат.
3)
+
P
(3<
X
<
x
)
,
получим указанный результат.
Итак, получена искомая интегральная функция распределения случайной величины Х:
F
(x
)
=

график которой изображен на рис. 4.2.

3) Математическое ожидание дискретной случайной величины равно сумме произведений всех возможных значений Х на их вероятности:
М(Х) =0=1,2.
То есть, в среднем происходит одно попадание в цель при трех выстрелах.
Дисперсию можно вычислить, исходя из
определения дисперсии D
(X
)=
M
(X
-
M
(X
))
 или воспользоваться формулойD
(X
)=
M
(X
или воспользоваться формулойD
(X
)=
M
(X ,
которая ведет к цели быстрее.
,
которая ведет к цели быстрее.
Напишем закон распределения случайной
величины Х :
:
Найдем математическое ожидание для Х
 :
:
М(Х )
= 04
)
= 04 = 2,16.
= 2,16.
Вычислим искомую дисперсию:
D
(X
)
=
M
(X )
– (M
(X
))
)
– (M
(X
))
 = 2,16 – (1,2)
= 2,16 – (1,2) = 0,72.
= 0,72.
Среднее квадратическое отклонение найдем по формуле
 (X
)
=
(X
)
=
 = 0,848.
= 0,848.
Интервал (M
-
 ;
M
+
;
M
+
 )
= (1,2-0,85; 1,2+0,85) = (0,35; 2,05) – интервал
наиболее вероятных значений случайной
величиныХ
, в него попадают значения
1 и 2.
)
= (1,2-0,85; 1,2+0,85) = (0,35; 2,05) – интервал
наиболее вероятных значений случайной
величиныХ
, в него попадают значения
1 и 2.
Пример 4.8.
Дана дифференциальная функция распределения (функция плотности) непрерывной случайной величины Х :
 f
(x
)
=
f
(x
)
=
1) Определить постоянный параметр a .
2) Найти интегральную функцию F (x ) .
3) Построить графики функций f (x ) иF (x ) .
4) Найти двумя способами вероятности
Р(0,5<
X 1,5)
иP
(1,5<
X
<3,5)
.
1,5)
иP
(1,5<
X
<3,5)
.
5). Найти математическое ожидание М(Х)
,
дисперсиюD
(Х)
и
среднее квадратическое отклонение
 случайной величиныХ
.
случайной величиныХ
.
Решение
1) Дифференциальная функция по свойству
f
(x
)
должна удовлетворять условию .
.
Вычислим этот несобственный интеграл для данной функции f (x ) :

Подставляя этот результат в левую часть
равенства, получим, что а
=1. В условии
дляf
(x
)
заменим параметра
на 1:

2) Для нахождения F (x ) воспользуемся формулой
 .
.
Если х ,
то
,
то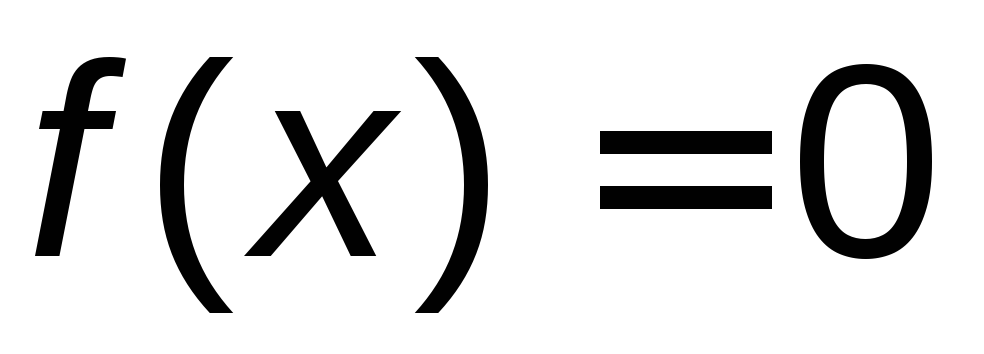 ,
следовательно,
,
следовательно,
Если 1 то
то
Если x>2, то
Итак, искомая интегральная функция F (x ) имеет вид:

3) Построим графики функций f (x ) иF (x ) (рис. 4.3 и 4.4).


4) Вероятность попадания случайной
величины в заданный интервал (а,
b
)
вычисляется по формуле
 ,
если известнафункция
f
(x
),
и по формуле P
(a
<
X
<
b
)
=
F
(b
)
–
F
(a
),
если известна
функция
F
(x
).
,
если известнафункция
f
(x
),
и по формуле P
(a
<
X
<
b
)
=
F
(b
)
–
F
(a
),
если известна
функция
F
(x
).
Найдем
 по двум формулам и сравним результаты.
По условиюа=0,5;
b
=1,5;
функцияf
(X
)
задана в пункте 1). Следовательно,
искомая вероятность по формуле равна:
по двум формулам и сравним результаты.
По условиюа=0,5;
b
=1,5;
функцияf
(X
)
задана в пункте 1). Следовательно,
искомая вероятность по формуле равна:
Та же вероятность может быть вычислена по формуле b) через приращение полученной в п.2). интегральной функцииF (x ) на этом интервале:
Так какF (0,5)=0.
Аналогично находим
так как F (3,5)=1.
5) Для нахождения математического
ожидания М(Х)
воспользуемся формулой
 Функцияf
(x
)
задана в решении пункта 1), она равна
нулю вне интервала (1,2]:
Функцияf
(x
)
задана в решении пункта 1), она равна
нулю вне интервала (1,2]:

 Дисперсия
непрерывной случайной величиныD
(Х)
определяется равенством
Дисперсия
непрерывной случайной величиныD
(Х)
определяется равенством
 ,
или равносильным равенством
,
или равносильным равенством

 .
.
Для нахожденияD
(X
)
воспользуемся последней формулой и
учтем, что все возможные значенияf
(x
)
принадлежат интервалу (1,2]:
нахожденияD
(X
)
воспользуемся последней формулой и
учтем, что все возможные значенияf
(x
)
принадлежат интервалу (1,2]:
Среднее квадратическое отклонение
 =
= =0,276.
=0,276.
Интервал наиболее вероятных значений случайной величины Х равен
(М- ,М+
,М+ )
= (1,58-0,28; 1,58+0,28) = (1,3; 1,86).
)
= (1,58-0,28; 1,58+0,28) = (1,3; 1,86).